
unMORE: Unsupervised Multi-Object Segmentation via Center-Boundary Reasoning
Y. Yang, Z. Zhang, B. Yang
International Conference on Machine Learning (ICML), 2025
arXiv /
Code
We present a new two-stage pipeline to identify many complex objects in real-world images without supervision.
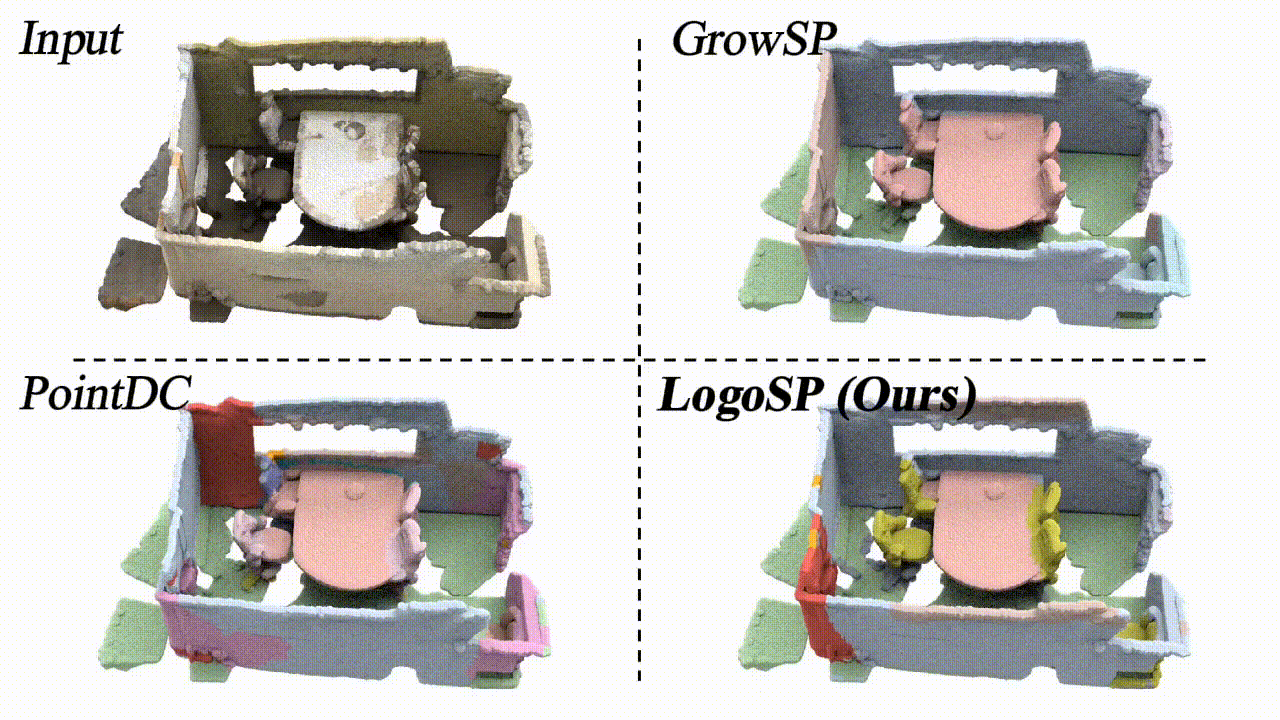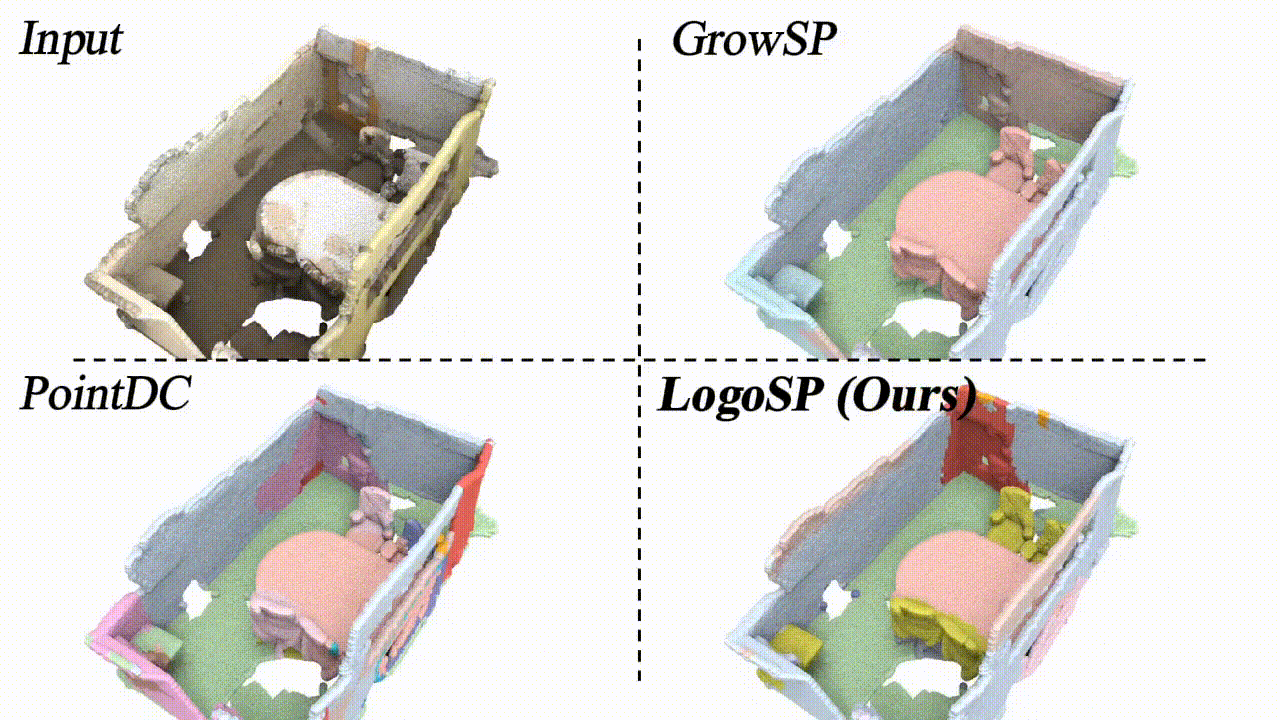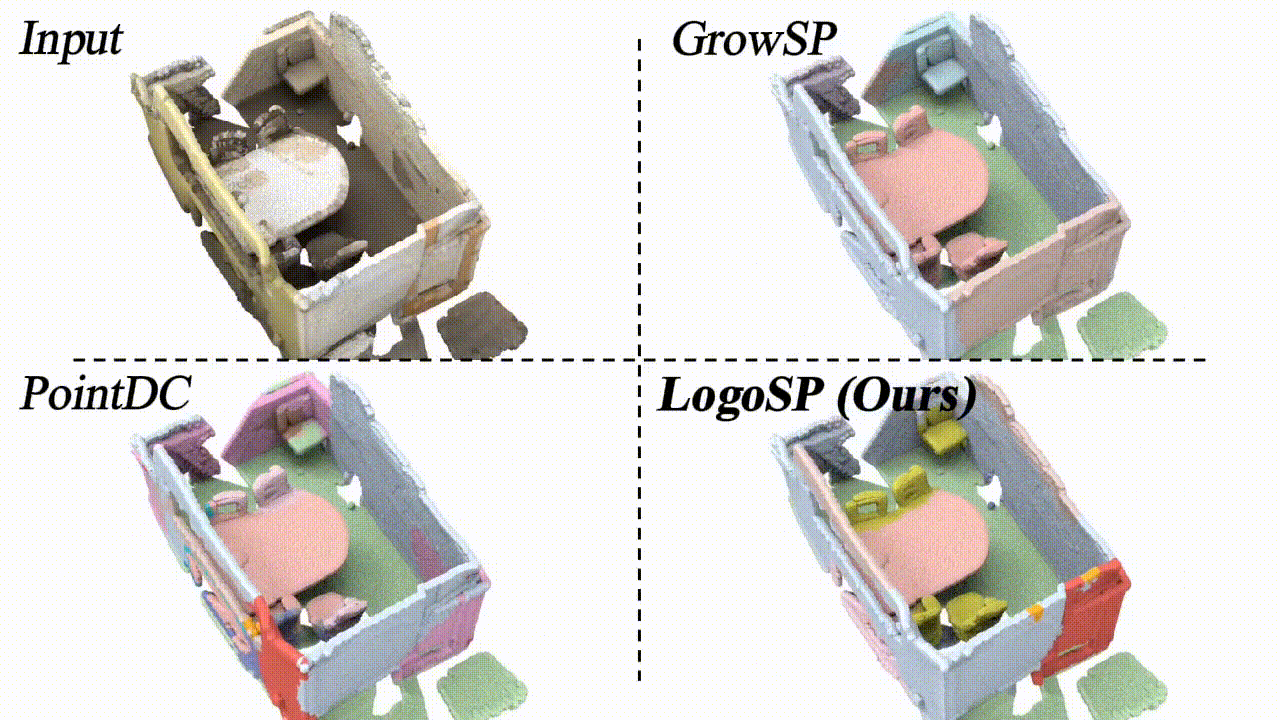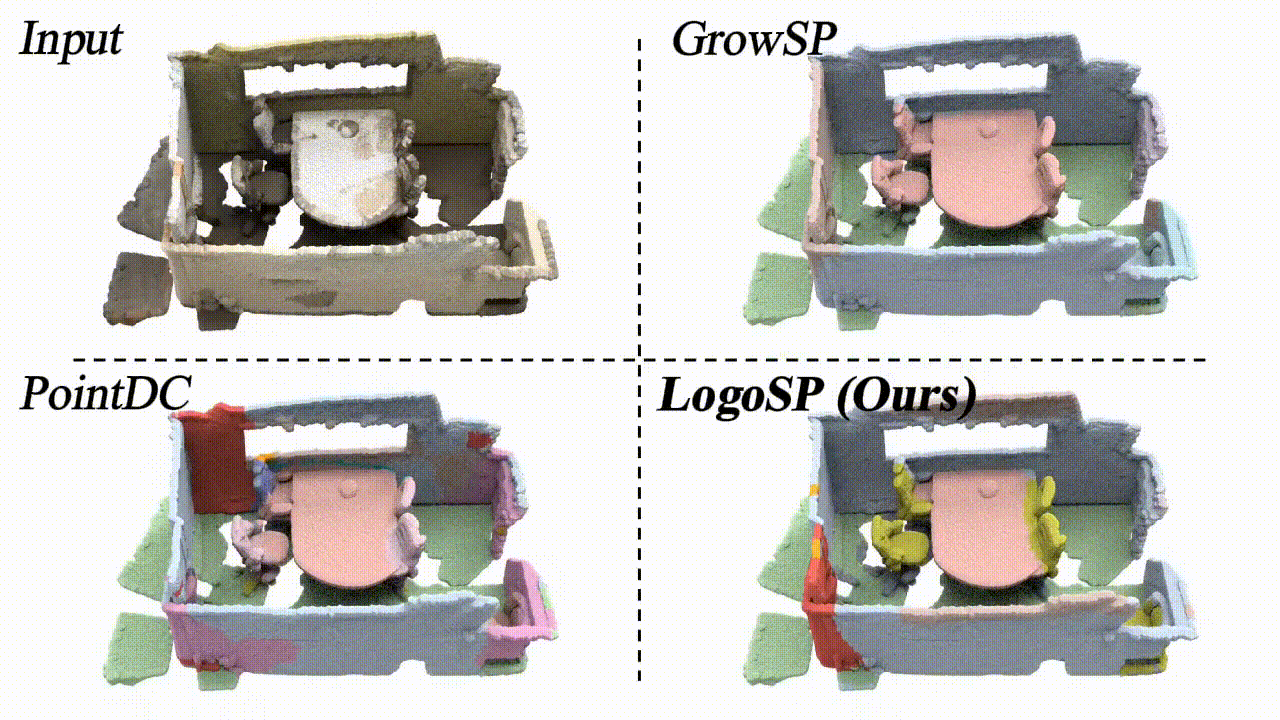
LogoSP: Local-global Grouping of Superpoints for Unsupervised Semantic Segmentation of 3D Point Clouds
Z. Zhang, W. Dai, H. Wen, B. Yang
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2025
arXiv /
Code
We present a new unsupervised learning method for 3D semantic segmentation, achieving SOTA performance.
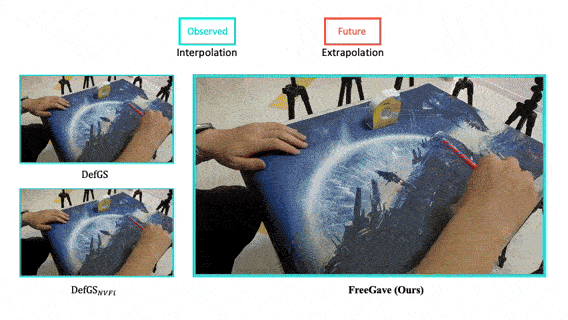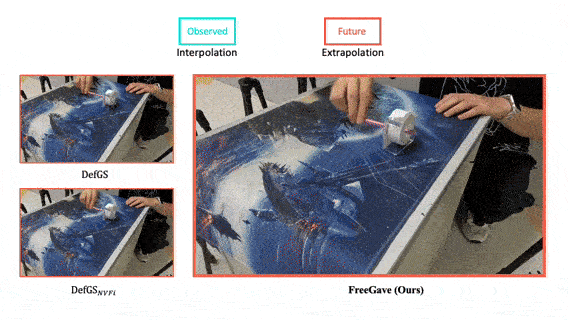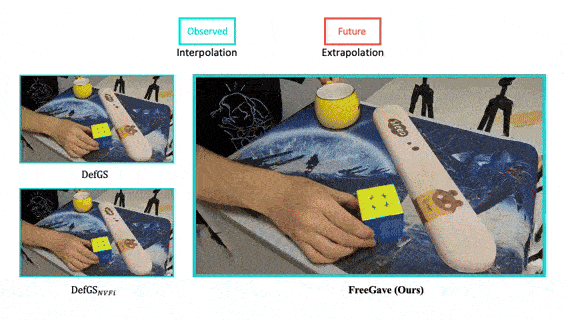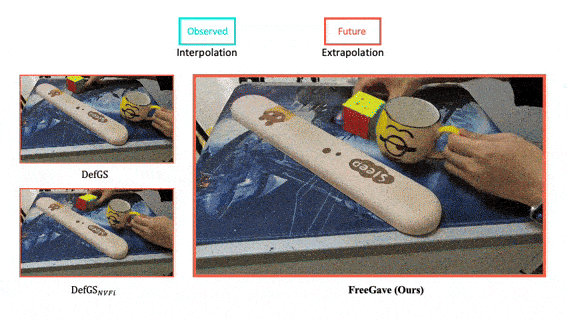
FreeGave: 3D Physics Learning from Dynamic Videos by Gaussian Velocity
J. Li, Z. Song, S. Zhou, B. Yang
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2025
arXiv /
Code
We present a new framework that learns 3D geometry, appearance and velocity purely from multi-view videos, achieving SOTA performance in future extrapolation.

GrabS: Generative Embodied Agent for 3D Object Segmentation without Scene Supervision
Z. Zhang, Y. Yang, H. Wen, B. Yang
International Conference on Learning Representations (ICLR), 2025 (Spotlight, 380/11672)
arXiv /
Code
We present the first agent-based framework for unsupervised 3D object segmentation on point clouds.

OSN: Infinite Representations of Dynamic 3D Scenes from Monocular Videos
Z. Song, J. Li, B. Yang
International Conference on Machine Learning (ICML), 2024
arXiv /
Code
We present the first framework to represent dynamic 3D scenes in infinitely many ways from a monocular RGB video.
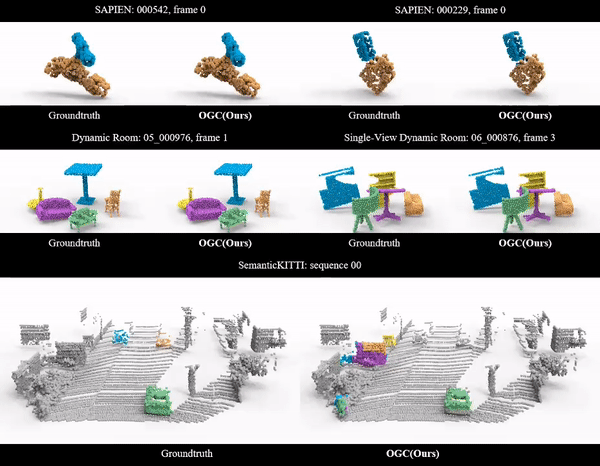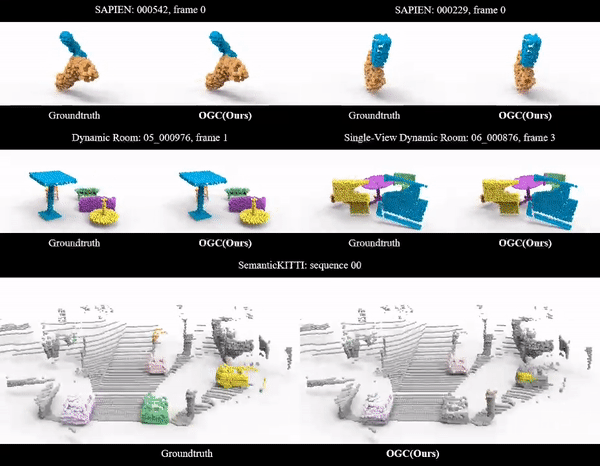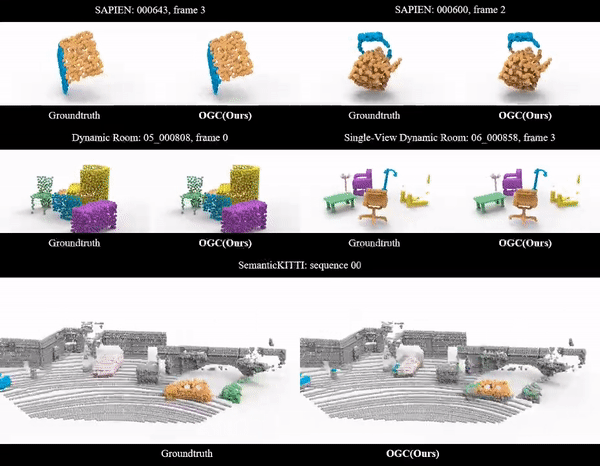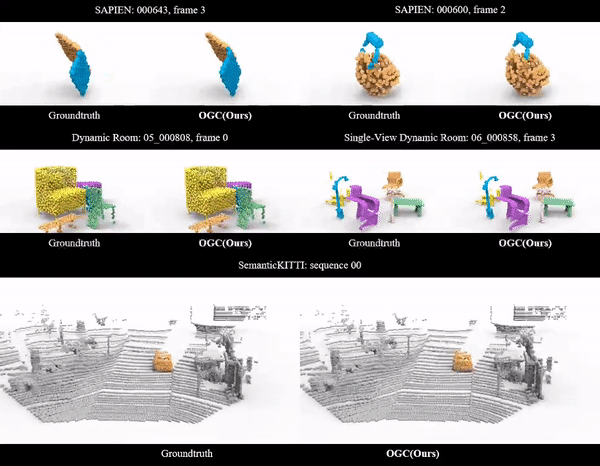
Unsupervised 3D Object Segmentation of Point Clouds by Geometry Consistency
Z. Song, B. Yang
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2024 (IF=20.8)
IEEE Xplore /
Code
The journal version of our OGC at NeurIPS 2022. More experiments and analysis are included.

Learning to Catch Reactive Objects with a Behavior Predictor
K. Lu, JX. Zhong, B. Yang, B. Wang, A. Markham
IEEE International Conference on Robotics and Automation (ICRA), 2024
Project Page
We present a novel framework to track and catch reactive objects in a dynamic 3D world.

Benchmarking and Analysis of Unsupervised Object Segmentation from Real-World Single Images
Y. Yang, B. Yang
International Journal of Computer Vision (IJCV), 2024 (IF=11.6)
arXiv /
Springer Access /
Code
The journal version of our paper at NeurIPS 2022. Complete benchmark and analysis are included.
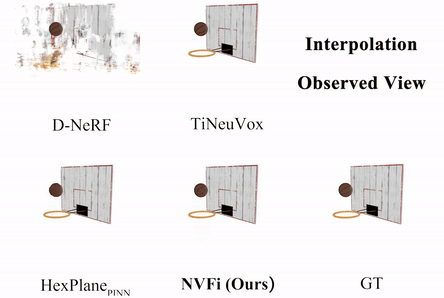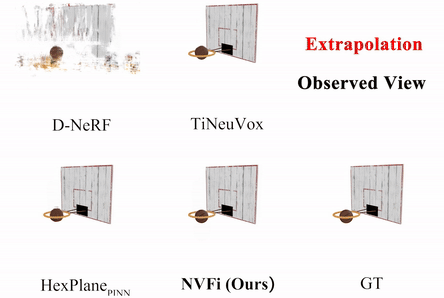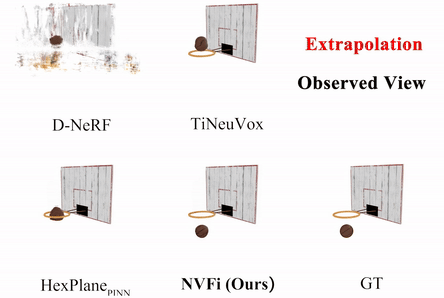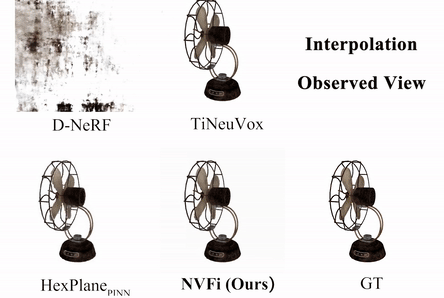
NVFi: Neural Velocity Fields for 3D Physics Learning from Dynamic Videos
J. Li, Z. Song, B. Yang
Advances in Neural Information Processing Systems (NeurIPS), 2023
arXiv /
Code
We present a novel framework to simultaneously learn the geometry, appearance, and physical velocity of 3D scenes.

RayDF: Neural Ray-surface Distance Fields with Multi-view Consistency
Z. Liu, B. Yang*, Y. Luximon, A. Kumar, J. Li
Advances in Neural Information Processing Systems (NeurIPS), 2023
arXiv /
Project Page /
Code
(* indicates corresponding author)
We propose a novel ray-based 3D shape representation, achieving a 1000x faster speed in rendering.

GrowSP: Unsupervised Semantic Segmentation of 3D Point Clouds
Z. Zhang, B. Yang*, B. Wang, B. Li
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023
arXiv /
Code
(* indicates corresponding author)
We propose the first unsupervised 3D semantic segmentation method, learning from growing superpoints in point clouds.

DM-NeRF: 3D Scene Geometry Decomposition and Manipulation from 2D Images
B. Wang, L. Chen, B. Yang*
International Conference on Learning Representations (ICLR), 2023
arXiv /
Tweet /
Code
(* indicates corresponding author)
We introduce a single pipeline to simultaneously reconstruct, decompose, manipulate and render complex 3D scenes.

Decoupling Skill Learning from Robotic Control for Generalizable Manipulation
K. Lu, B. Yang, B. Wang, A. Markham
IEEE International Conference on Robotics and Automation (ICRA), 2023
Project Page
We propose a generalizable framework for robotic manipulation.
OGC: Unsupervised 3D Object Segmentation from Rigid Dynamics of Point Clouds
Z. Song, B. Yang
Advances in Neural Information Processing Systems (NeurIPS), 2022
arXiv /
Video /
Code
We introduce the first unsupervised 3D object segmentation method on point clouds.
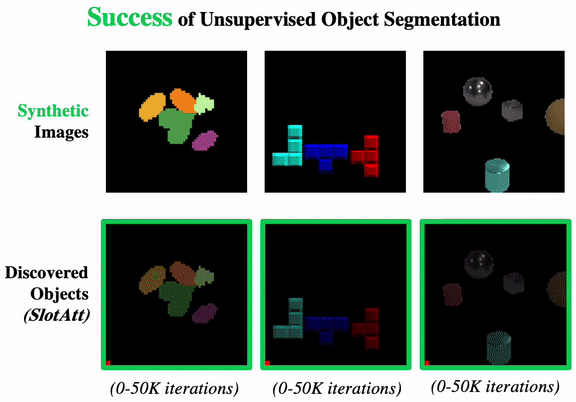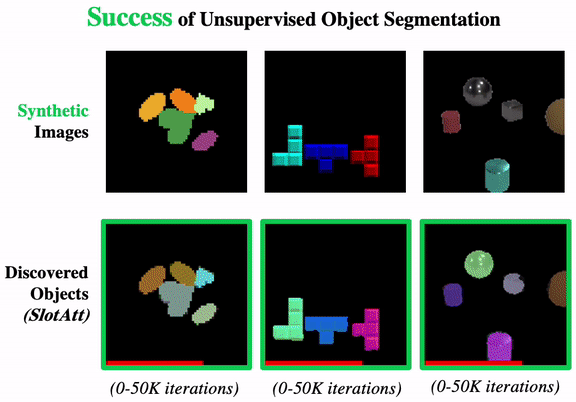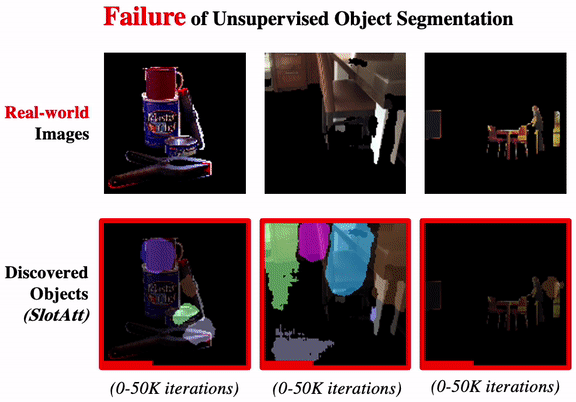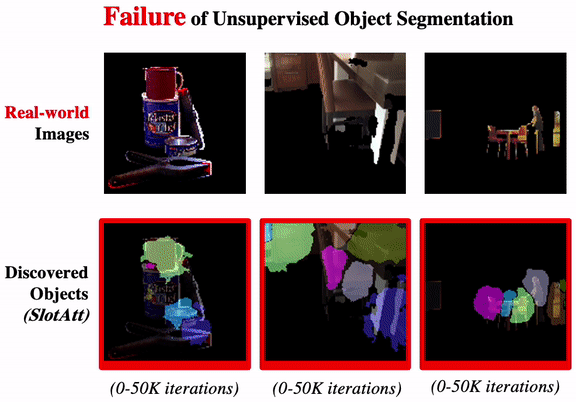
Promising or Elusive? Unsupervised Object Segmentation from Real-world Single Images
Y. Yang, B. Yang
Advances in Neural Information Processing Systems (NeurIPS), 2022
arXiv /
Project Page /
Code
We systematically investigate the effectiveness of existing unsupervised models on challenging real-world images.

SQN: Weakly-Supervised Semantic Segmentation of Large-Scale 3D Point Clouds
Q. Hu, B. Yang*, G. Fang, Y. Guo, A. Leonardis, N. Trigoni, A. Markham
European Conference on Computer Vision (ECCV), 2022
arXiv /
Code
(* indicates corresponding author)
We introduce a simple weakly-supervised neural network to learn precise 3D semantics for large-scale point clouds.
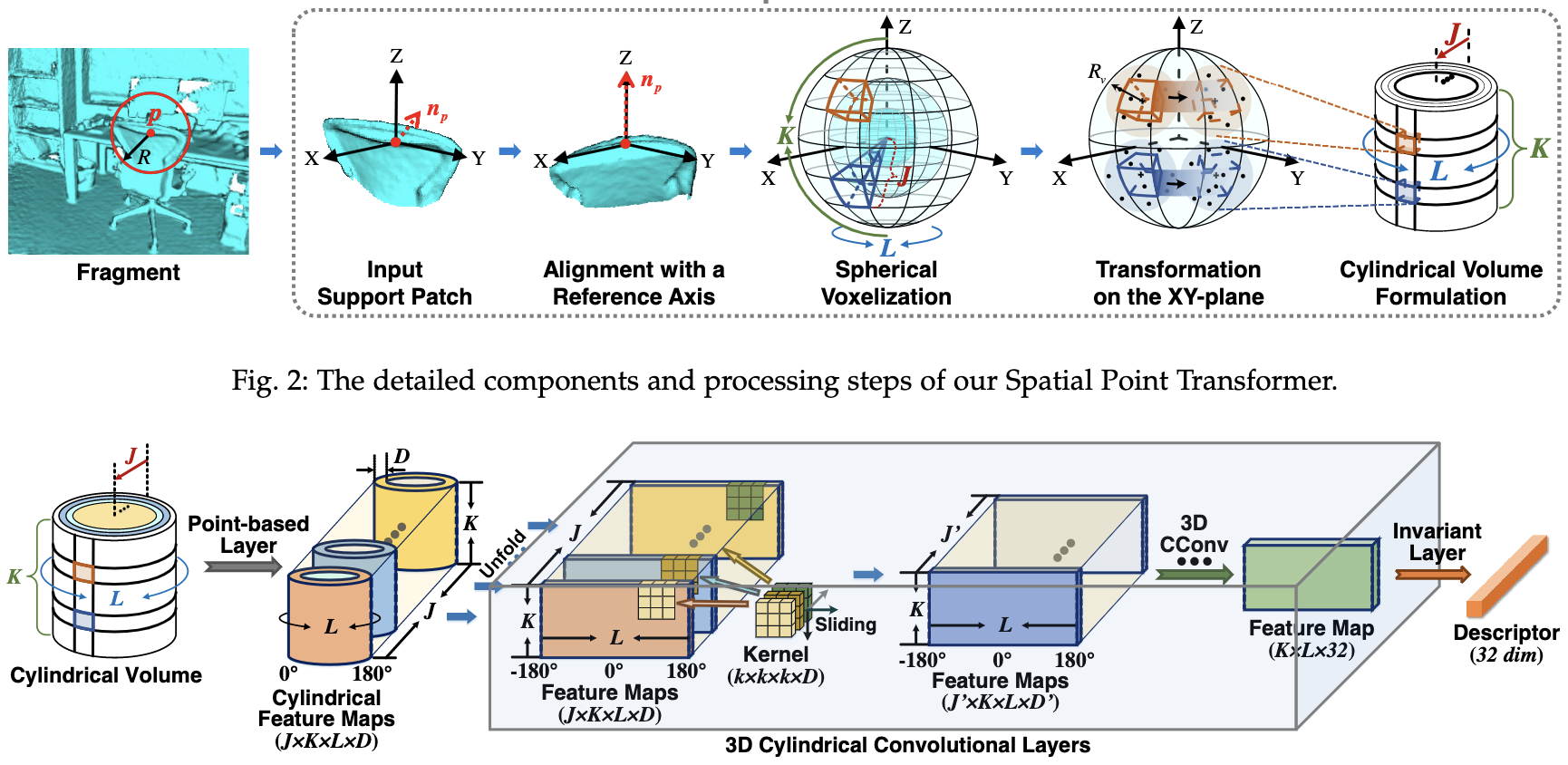
You Only Train Once: Learning General and Distinctive 3D Local Descriptors
S. Ao, Y. Guo, Q. Hu, B. Yang, A. Markham, Z. Chen
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2022 (IF=16.39)
IEEE Xplore /
Code
The journal version of our SpinNet. More experiments and analysis are included.

RangeUDF: Semantic Surface Reconstruction from 3D Point Clouds
B. Wang, Z. Yu, B. Yang*, J. Qin, T. Breckon, L. Shao, N. Trigoni, A. Markham
arXiv /
Demo /
Project page
(* indicates corresponding author)
We propose a new method to recover the geometry and semantics of continuous 3D scene surfaces from point clouds.

SensatUrban: Learning Semantics from Urban-Scale Photogrammetric Point Clouds
Q. Hu, B. Yang*, S. Khalid, W. Xiao, N. Trigoni, A. Markham
International Journal of Computer Vision (IJCV), 2022 (IF=7.41)
arXiv /
Springer Access /
Demo /
Project page
(* indicates corresponding author)
The journal version of our SensatUrban. More experiments and analysis are included.
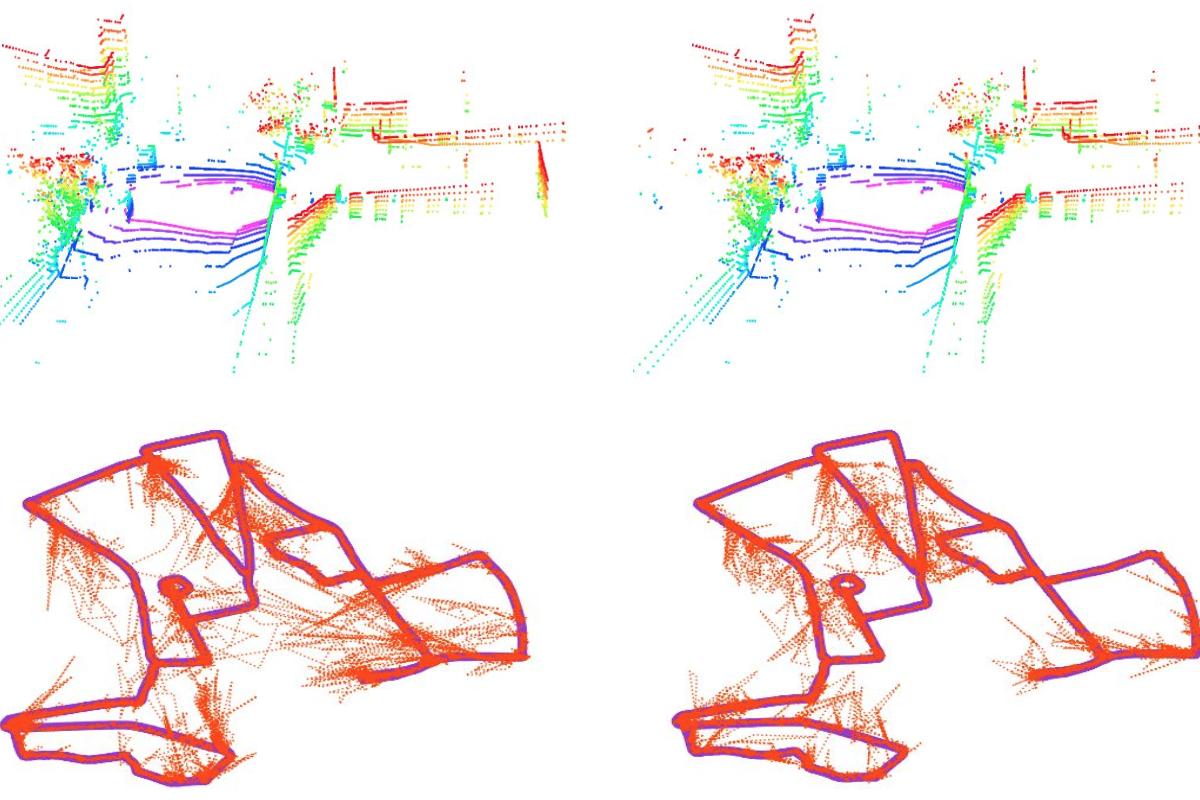
PointLoc: Deep Pose Regressor for LiDAR Point Cloud Localization
Wei Wang, Bing Wang, Peijun Zhao, Changhao Chen, Ronald Clark, B. Yang, Andrew Markham, Niki Trigoni
IEEE Sensor Journal, 2022 (IF=3.30)
arXiv /
IEEE Xplore
We present a learning-based LiDAR relocalization framework to efficiently estimate 6-DoF poses from LiDAR point clouds.

GRF: Learning a General Radiance Field for 3D Representation and Rendering
A. Trevithick, B. Yang
IEEE International Conference on Computer Vision (ICCV), 2021
arXiv /
News:
CVer /
Code
We introduce a simple implicit neural function to represent complex 3D geometries purely from 2D images.

Learning Semantic Segmentation of Large-Scale Point Clouds with Random Sampling
Q. Hu, B. Yang*, L. Xie, S. Rosa, Y. Guo, Z. Wang, N. Trigoni, A. Markham
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2021 (IF=16.39)
arXiv /
IEEE Xplore /
Code
(* indicates corresponding author)
The journal version of our RandLA-Net. More experiments and analysis are included.
SpinNet: Learning a General Surface Descriptor for 3D Point Cloud Registration
S. Ao^, Q. Hu^, B. Yang, A. Markham, Y. Guo
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021
arXiv /
Code
(^ indicates equal contributions)
We introduce a simple and general neural network to register pieces of 3D point clouds.

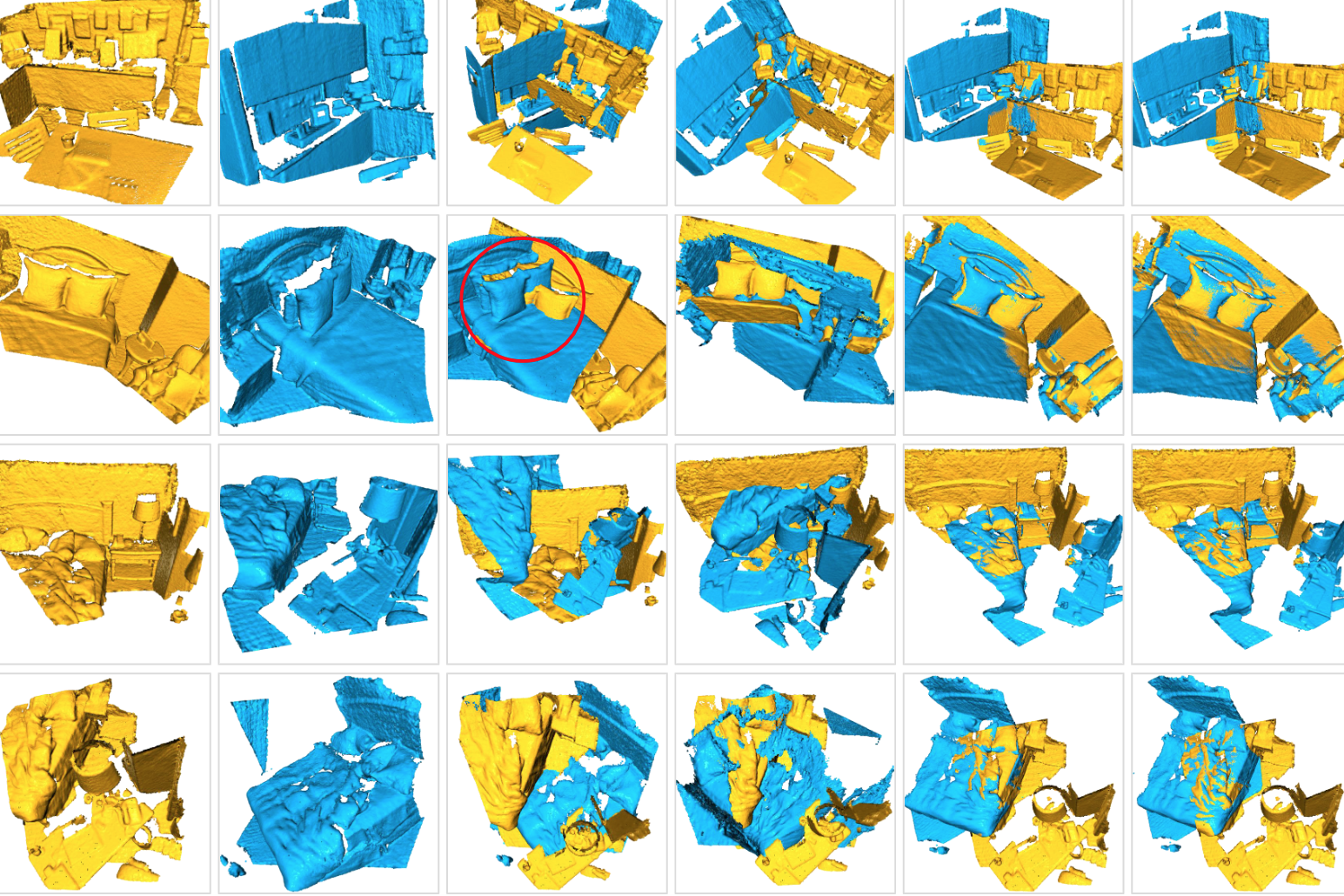
Towards Semantic Segmentation of Urban-Scale 3D Point Clouds: A Dataset, Benchmarks and Challenges
Q. Hu, B. Yang*, S. Khalid, W. Xiao, N. Trigoni, A. Markham
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021
arXiv /
Demo /
Project page
(* indicates corresponding author)
We introduce an urban-scale photogrammetric point cloud dataset and extensively evaluate and analyze the state-of-the-art algorithms on the dataset.
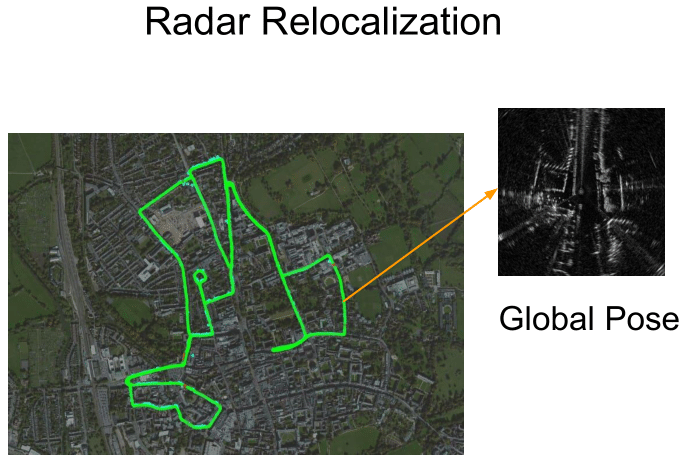
RadarLoc: Learning to Relocalize in FMCW Radar
W. Wang, P.P.B. de Gusmao, B. Yang, A. Markham, N. Trigoni
IEEE International Conference on Robotics and Automation (ICRA) , 2021
arXiv /
IEEE Xplore
We introduce a simple end-to-end neural network with self-attention to estimate global poses from FMCW radar scans.
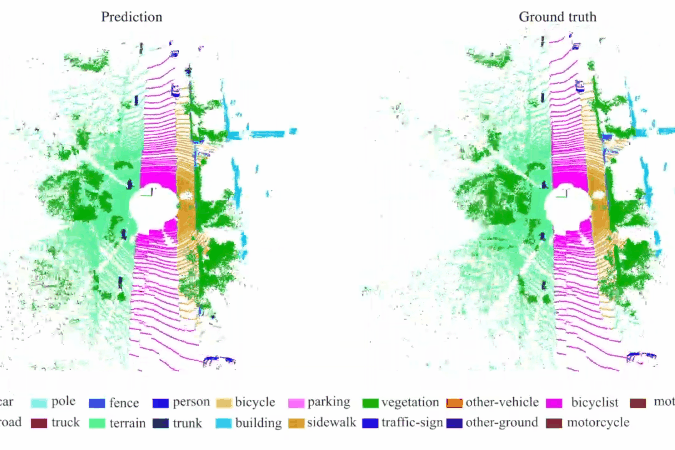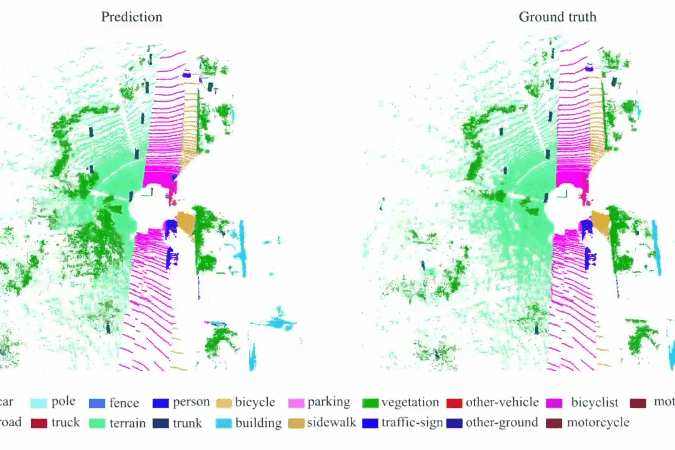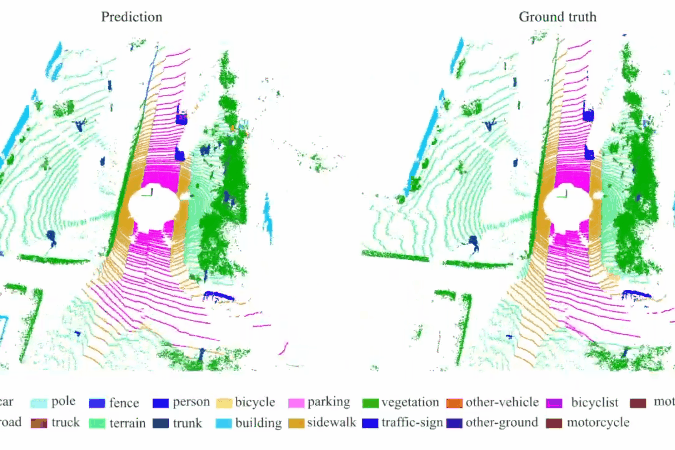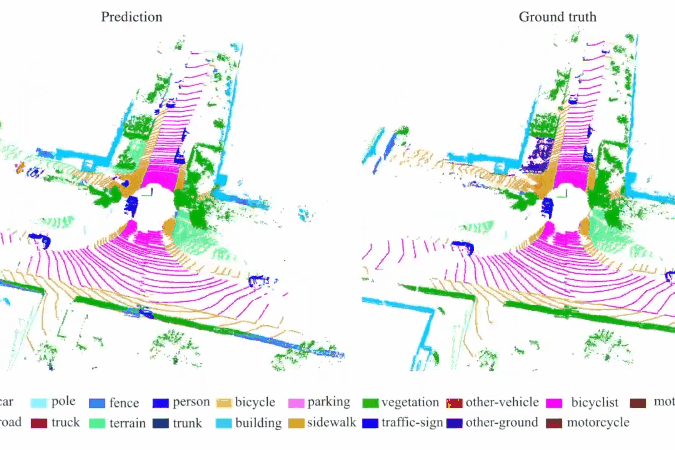
RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds
Q. Hu, B. Yang*, L. Xie, S. Rosa, Y. Guo, Z. Wang, N. Trigoni, A. Markham
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020
arXiv /
Semantic3D Benchmark /
News:
(新智元,
AI科技评论,
CVer) /
Video /
Code
(* indicates corresponding author)
We introduce an efficient and lightweight neural architecture to directly infer per-point semantics for large-scale point clouds.
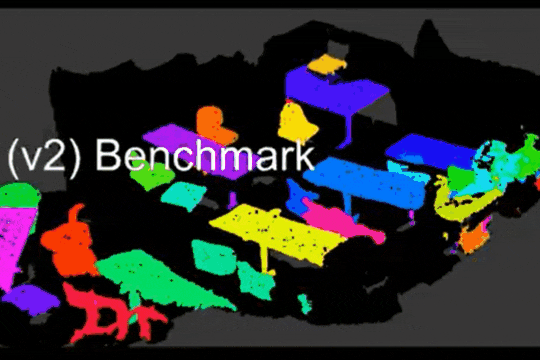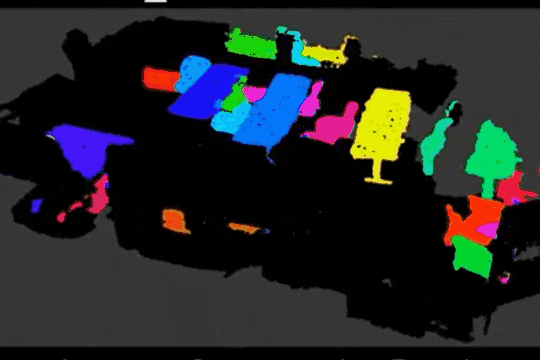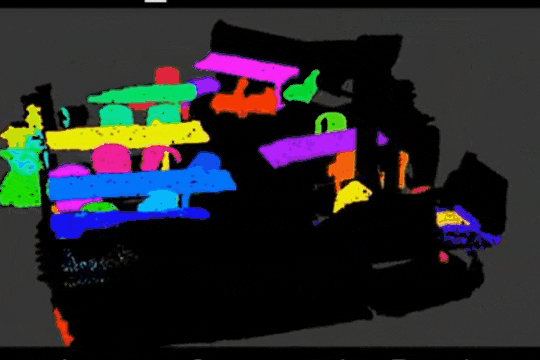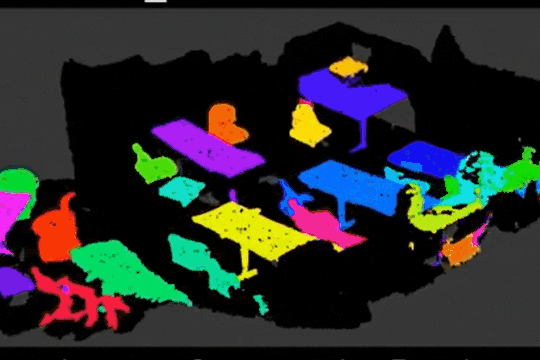
Learning Object Bounding Boxes for 3D Instance Segmentation on Point Clouds
B. Yang, J. Wang, R. Clark, Q. Hu, S. Wang, A. Markham, N. Trigoni
Advances in Neural Information Processing Systems (NeurIPS), 2019 (Spotlight, 200/6743)
arXiv /
ScanNet Benchmark /
Reddit Discussion /
News:
(新智元,
图像算法,
AI科技评论,
将门创投,
CVer,
泡泡机器人) /
Video /
Code
We propose a simple and efficient neural architecture for accurate 3D instance segmentation on point clouds. It achieves the SOTA performance on ScanNet and S3DIS (June 2019).
DeepPCO: End-to-End Point Cloud Odometry through Deep Parallel Neural Network
W. Wang, M.R.U. Saputra, P. Zhao, P. Gusmao, B. Yang, C. Chen, A. Markham, N. Trigoni
IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2019
arXiv /
IEEE Xplore
We propose a novel end-to-end deep parallel neural network to estimate the 6-DOF poses using consecutive 3D point clouds.

Robust Attentional Aggregation of Deep Feature Sets for Multi-view 3D Reconstruction
B. Yang, S. Wang, A. Markham, N. Trigoni
International Journal of Computer Vision (IJCV), 2019 (IF=6.07)
arXiv /
Springer Open Access /
Code
We propose an attentive aggregation module together with a training algorithm for multi-view 3D object reconstruction.

Learning Semantically Meaningful Embeddings Using Linear Constraints
S. Lin, B. Yang, R. Birke, R. Clark
IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPR-W), 2019
CVF Open Access
We propose a simple embedding learning method that jointly optimises for an auto-encoding reconstruction task and for estimating the corresponding attribute labels.

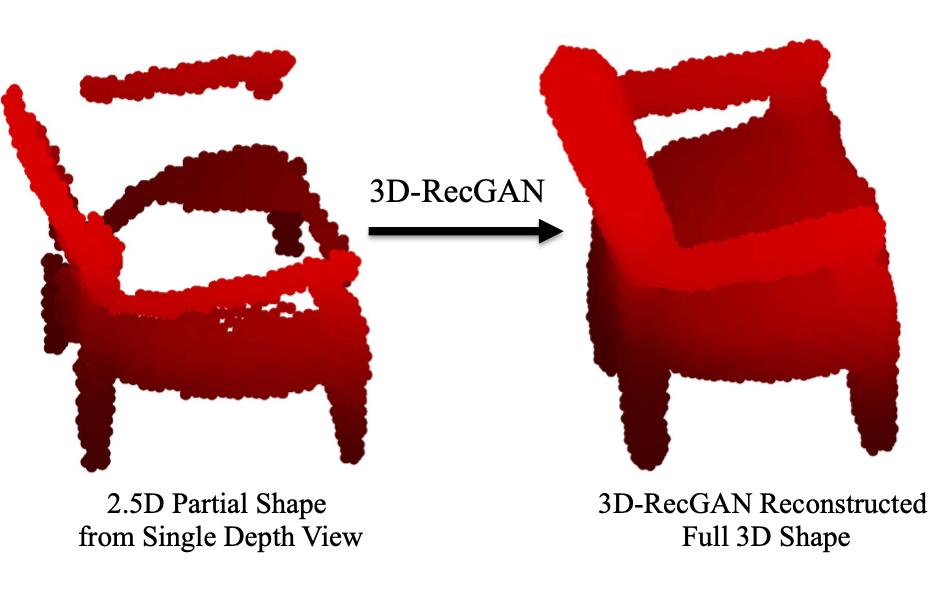
Dense 3D Object Reconstruction from a Single Depth View
B. Yang, S. Rosa, A. Markham, N. Trigoni, H. Wen
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2018 (IF=17.73)
arXiv /
IEEE Xplore /
Code
We propose a novel neural architecture to reconstruct the complete 3D structure of a given object from a single arbitrary depth view using generative adversarial networks.

3D-PhysNet: Learning the Intuitive Physics of Non-Rigid Object Deformations
Z. Wang, S. Rosa, B. Yang, S. Wang, N. Trigoni, A. Markham
International Joint Conference on Artificial Intelligence (IJCAI), 2018
arXiv /
Code
We present a neural framework to predict how a 3D object will deform under an applied force using intuitive physics modelling.
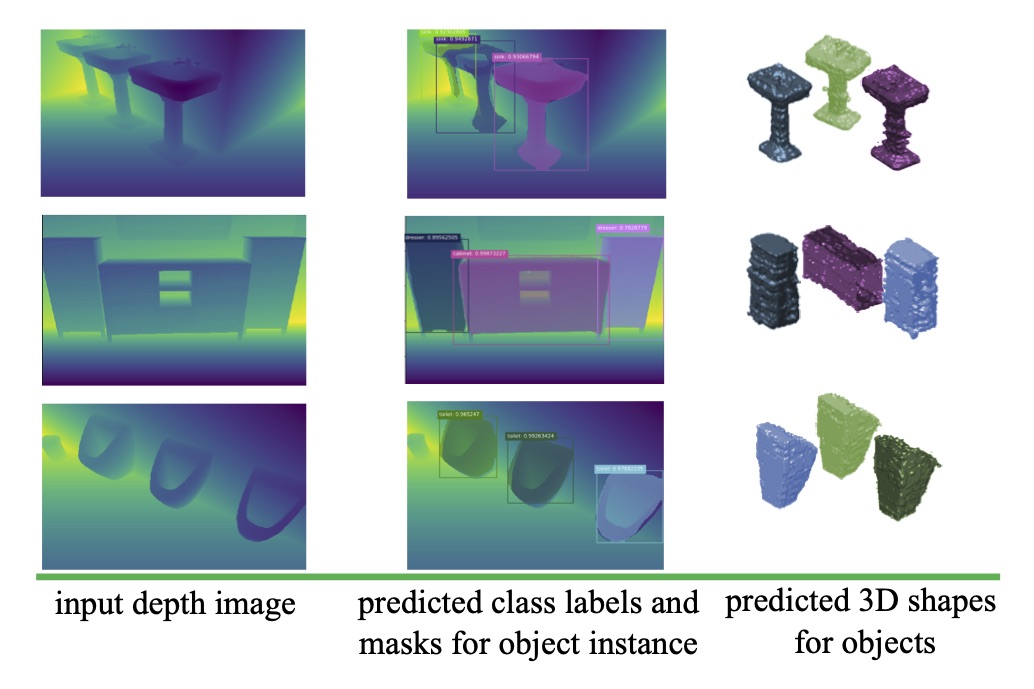
Learning 3D Scene Semantics and Structure from a Single Depth Image
B. Yang*, Z. Lai*, X. Lu, S. Lin, H. Wen, A. Markham, N. Trigoni
IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPR-W), 2018
CVF Open Access /
IEEE Xplore
(* indicates equal contribution)
We propose an efficient and holistic pipeline to simultaneously learn the semantics and structure of a scene from a single depth image.
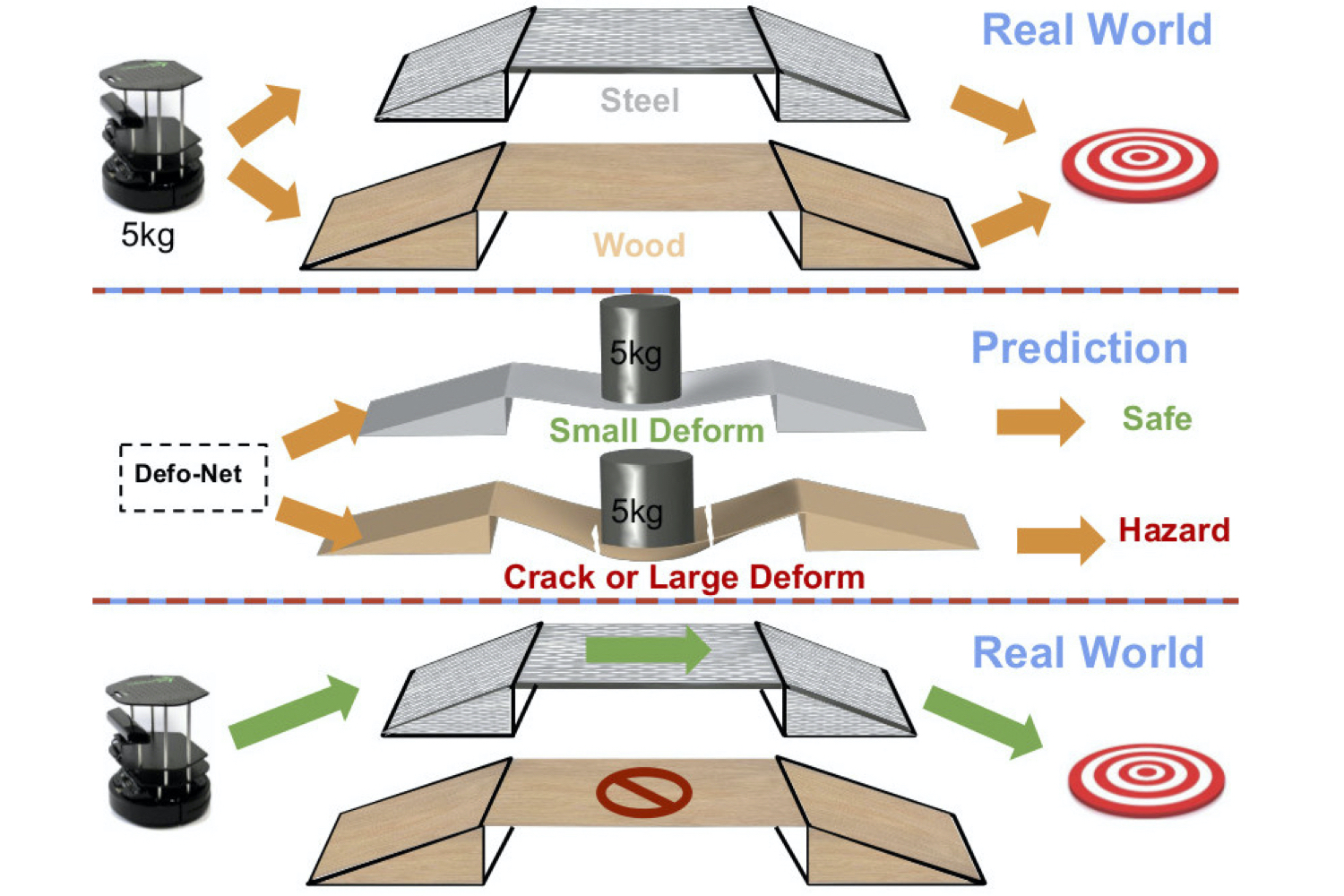
Defo-Net: Learning Body Deformation Using Generative Adversarial Networks
Z. Wang, S. Rosa, L. Xie, B. Yang, S. Wang, N. Trigoni, A. Markham
IEEE International Conference on Robotics and Automation (ICRA) , 2018
arXiv /
IEEE Xplore /
Video /
Code
We present a novel generative adversarial network to predict body deformations under external forces from a single RGB-D image.
3D Object Reconstruction from a Single Depth View with Adversarial Learning
B. Yang, H. Wen, S. Wang, R. Clark, A. Markham, N. Trigoni
IEEE International Conference on Computer Vision Workshops (ICCV-W) , 2017
arXiv /
IEEE Xplore /
News: 机器之心 /
Code
We propose a novel approach to reconstruct the complete 3D structure of a given object from a single arbitrary depth view using generative adversarial networks.